
Blog
Common Sense on Climate Change
Some common sense on Climate Change – what does the science really say?
Net Zero
Time for a proper debate about Net Zero:
The Precautionary Principle – care required!
In a number of spheres, from environmental issues to public heath there is a growing tendency for the precautionary principle to be adopted in decision making. At one level, this is understandable. When faced with a clearly life-threatening situation it is better to be safe than sorry by choosing not to do something. If a grizzly bear is known to be in the vicinity then it may be wise to stay indoors until the threat has passed (or someone else has dealt with it).
However, I would argue that the use of the precautionary principle when it comes to complex risk decisions is a cop out by decision-makers. The principle is too often employed with an over-riding focus on a single issue e.g. climate change or an epidemic, and thereby over-simplifies the problem. What is neglected (intentionally or unintentionally) is the fact that every decision has consequences. The benefits of any particular course of action always incurs a cost. When it comes to risk, any decision always entails a trade-off between a cost and a benefit. The benefit has to outweigh the cost and not just marginally but there has to be a sense of proportion. In other words, the price we’re prepared to pay must be worthwhile – we don’t pay any price for a marginal increase in benefit.
The precautionary principle inherently neglects these inevitable trade-offs and the principle of gross disproportion. It also tends to be employed when there is a high degree of uncertainty over the outcome. It’s attractive in this regard because all sorts of exaggerated claims can be made about the consequences of carrying on as normal without the ability to prove or disprove them. Fear is a powerful ally.
Engineers need to do better than revert to the precautionary principle when faced with difficult and complex problems.
Positions on Climate Change
Are we now heading to a world in which you are no longer able as a professional engineer to weigh up the evidence, assess the risks and then take appropriate actions which make most efficient use of resources?
It seems that way.
I’m increasingly disturbed by the adoption of Climate Change alarmism in defining what I can and can’t do as a professional engineer.
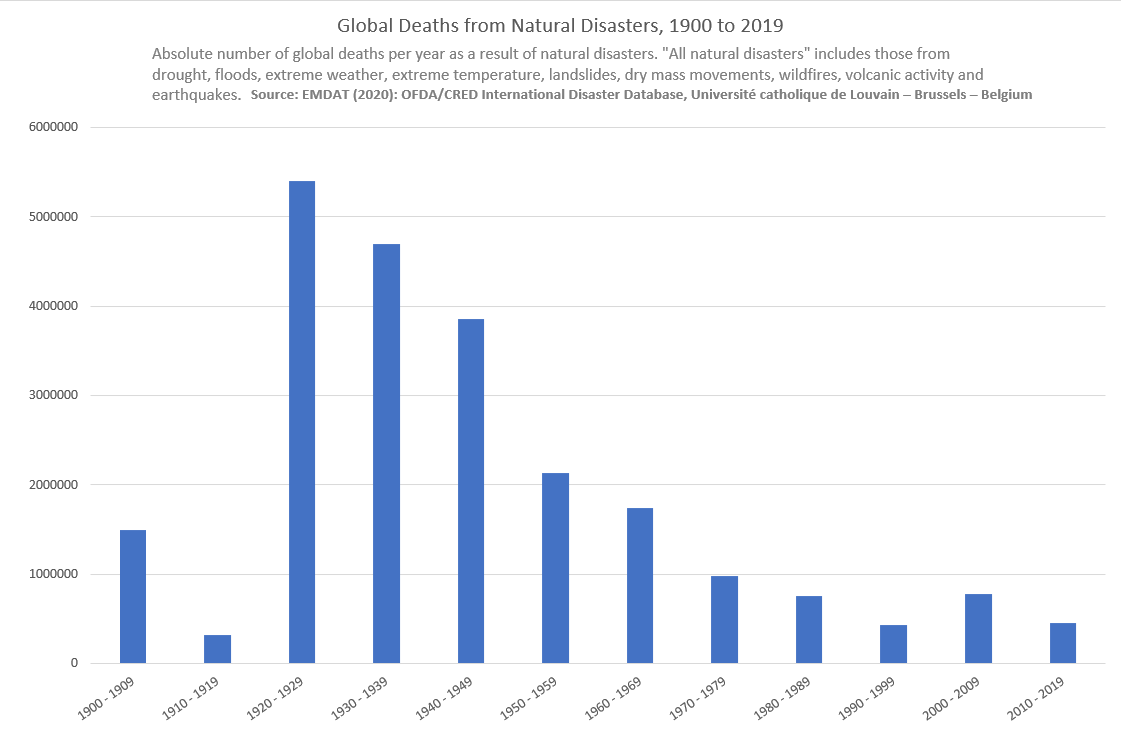
There has been a wholesale and headlong plunge into Net Zero based on catastrophising about the implications of a 1.5°C increase in global mean temperature. Common sense and engineering principles are being dispensed with in favour of what amounts to fantasy and doomsday thinking. Millions of people aren’t going to die from climate change. The number of deaths from natural disasters has decreased in the last century despite rising levels of carbon dioxide and global mean temperature increases.
Where is the evidence that there is a climate emergency? On what basis does reducing carbon dioxide emissions make for the best solution to tackling economic poverty? What are the real benefits of Net Zero and to whom do they accrue? In the list of sustainable goals defined by the UN is climate change really the most pressing problem or would we be better tackling economic growth in the developing world by providing access to cheap high density energy?
As an engineer I am bound by a code of professional conduct:
Members when discharging their professional duties shall act with competence and integrity, in the public interest, and shall exercise all reasonable professional skill and care to: (a) Professional competence (i)Prevent avoidable danger to health or safety (ii) Prevent avoidable adverse impact on the environment.
(Code of Professional Conduct and Disciplinary Regulations Issue V: 2015 IChemE)
At the minute this leaves room to define the problem accurately, establish the options, assess those options against criteria (societal, health, safety, environment and economic), and then decide upon the optimal course of action. Changing a professional code of conduct to align with a specific solution to an ill-defined problem is wrong-headed.
There needs to be a better informed debate about this whole subject and how best to define and tackle the problems. A couple of good places to start:
https://environmentalprogress.org/
Fukushima

Some notable and sobering quotes from “The Offical Report of The Fukushima Nuclear Accident Independent Investigation Commission” published by the National Diet of Japan and chaired by Kiyoshi Kurokawa (2012).
- It was a profoundly man-made disaster – that could and should have been foreseen and prevented.
- What must be admitted – very painfully – is that this was a disaster “Made in Japan.” Its fundamental causes are to be found in the ingrained conventions of Japanese culture: our reflexive obedience; our reluctance to question authority; our devotion to ‘sticking with the program’; our groupism; and our insularity.
- The regulators should have taken a strong position on behalf of the public, but failed to do so. As they had firmly committed themselves to the idea that nuclear power plants were safe, they were reluctant to actively create new regulations.
- We have concluded that—given the deficiencies in training and preparation—once the total station blackout occurred, including the loss of a direct power source, it was impossible to change the course of events.
- In spite of the fact that TEPCO and the regulators were aware of the risk from such natural disasters, neither had taken steps to put preventive measures in place. It was this lack of preparation that led to the severity of this accident.
- The Japanese nuclear industry has fallen behind the global standard of earthquake and tsunami preparedness, and failed to reduce the risk of severe accidents by adhering to the five layers of the defense-in-depth strategy.
- The power supply system was especially poor from a defensive
perspective, and suffered from a lack of redundancy, diversity and independence. - A third issue was the arbitrary interpretation and selection of a probability theory. TEPCO tried to justify the belief that there was a low probability of tsunami, and used the results of a biased calculation process as grounds to ignore the need for countermeasures.
The P&ID Review – a Checklist

As a process engineer, one of the delights(!) awaiting you will be the P&ID review. Either, you’ll have responsibility for checking or approving P&IDs on a project (major or minor) generated within your organisation or provided by a supplier.
It’s one of those things that process engineers are expected to pick up on the job, usually by some form of osmosis, rather than helpful mentoring!
There’s one overriding principle to apply:
Think through the functions being served by each piece of equipment and continually ask whether what’s represented on the P&ID can fulfil each function. And remember the modes of operation, startup, shutdown and maintenance.
So here’s a checklist of things to look for:
-
- Is the purpose of the P&ID issue clear from the description e.g. Issued for HAZOP, Approved for Design etc.?
- Are all the notes accurately and appropriately referenced?
- Is the layout clear so that each line can be easily followed and not mistaken?
- Is there continuity of line numbering across each P&ID interface?
- Are there sufficient vents and drains to allow equipment to be prepared for maintenance or reinstated afterwards?
- Locate the HP/LP interfaces and ensure there is protection in place – either an open path to a relief device or vent, or a locked valve.
- Ensure piping specification breaks are clearly identified and line numbering follows the correct convention.
- Are the major process variables measured and controlled appropriately?
- Do the isolations e.g. double block and bleed, comply with the isolation philosophy?
- Are control valves clearly marked with the failure position on loss of motive fluid?
- Do the failure modes of control valves present a hazard?
- Are pressure boundaries respected when shutdown valves close?
- Are there open paths to blowdown valves from all equipment within each blowdown segment, to avoid locked in inventory?
- Are inlet lines to relief valves at least as large, if not larger than the inlet dimension?
- Ensure pressure relief paths are open.
- Are isolation valves upstream of relief valves locked in the correct position?
- Are isolation valves downstream of relief valves locked open (if present) even on standby relief valves?
- Are the slopes shown on lines in the correct direction to allow liquids to drain and not accumulate in the wrong places?
- Is there appropriate heat tracing and insulation provided on lines/bridles for winterisation?
- Is there appropriate insulation provided for personnel protection?
- Is instrumentation located suitably to avoid measurement interference?
- Are vents and drains to atmosphere which should normally be in the closed position shown with blanks or plugs?
- Are piping and instrumentation connected to the correct nozzles on equipment?
- Ensure there is no duplication of tag numbers.
Some flawed thinking
I recently came across a Safety Integrity Level (SIL) review of a high level trip on a production separator. Neither the relief valve nor the pressure control valve to flare off the top of the separator are sized for multiphase relief in the event that the liquid outlet should become blocked and the vessel overfill. These protective devices will therefore not stop the vessel overpressuring, especially as the upstream pressure from the wells is several times the design pressure of the separator. So you would think that the high level trip is quite important and intuitively should have a high SIL requirement.
The trip was assessed by Layer of Protection Analysis (LOPA). And this is where the flawed thinking arises. In the assessment, the worst case consequence was assumed to be an overpressure less than the corrected hydrotest pressure of the vessel on the basis that the relief valve and the pressure control valve would open allowing partial pressure relief. So credit is implicitly being taken of protective layers acting to limit the consequence. That’s bad enough logic, but then it is further compounded by claiming a probability of failure on demand (PFD) of 1 in 100 for the relief valve as an independent protective layer (IPL), in effect taking double credit for the relief valve. The end result is a low SIL requirement.
A correct assessment of the situation needs to start with the unmitigated consequence in the absence of any layers of protection – what’s the worst case pressure the vessel can experience and will it rupture? How often is this event likely to happen based on failure of the liquid level control. Then move on to consider what IPLs actually exist which fully mitigate the consequences. Clearly, if the relief valve and the pressure control valve are undersized for a blocked liquid outlet no credit can be taken for them. Even though they may act to limit the extent of the overpressure, their failure to act (which is assessed in LOPA) results in the worst case consequence and this needs to be considered in setting the SIL requirement for the high level trip.
LOPA is a simplified technique which can’t handle IPLs providing partial protection. There are other tools to evaluate this such as fault trees.
Always guard against the tendency to “bend” the rules of a particular technique beyond the bounds of its validity and end up with flawed thinking about an issue. It might be more painful to use a more sophisticated technique but the answer will be robust.
The need to get uncomfortable with the current reality
I’ve been chairing some Safety Integrity Level (SIL) assessments recently for an offshore asset in the North Sea of late 1980’s vintage. There have been multiple changes over the years with several subsea tiebacks added. Nothing out of the ordinary in that per se. However, what I’ve found intriguing is the preservation of past design standards alongside current standards on the one platform. For example, the high pressure/low pressure (HP/LP) interfaces on the original production separators are only protected by the downstream relief valve on the low pressure separator, and there is only a control valve at the interface – no independent shutdown valve to isolate the segments and no low level trip on the upstream vessel to prevent gas blowby. It’s 2019 with no apparent attempt to incorporate lessons learned from the Grangemouth Hydrocracker explosion in 1987: http://www.hse.gov.uk/comah/sragtech/casebpgrang87b.htm
Alongside this design, there are several high integrity pressure protection systems (HIPPS) protecting the HP/LP interface between the subsea systems and topsides reception facilities. These use a mixture of reactive and permissive type voted pressure trips acting on multiple shutdown valves to protect against failures which could result in the downstream relief valves being overwhelmed. Each subsequent subsea tieback seems to incorporate increasingly complex shutdown logic to accomplish the same protection. It took me the best part of a day to get to grips with the logic protecting one HP/LP interface – this may suggest it’s too complicated, which can be counter-productive in the long run.
This illustrates one of the challenges with managing change on old assets – simultaneously justifying the acceptance of outdated and vulnerable safety systems alongside the adoption of overly complex ones and thinking risk has been satisfactorily reduced as low as reasonably practicable.
Sometimes it’s worth taking time out to step back from the details of one specific system and to experience some discomfort about the reality of the situation to think more clearly about the overall design – is the protection in the right place, to the correct standard, and of appropriate complexity?
Some initial thoughts on process engineering in operations
I’ve worked a few times as a process engineer in an operational role directly supporting operations – an oil refinery hydrogen and hydrocracking unit, an oil stabilisation and gas fractionation terminal, and an oil producing FPSO. A grand total of ~10 years of not knowing what’s going to come your way from one day to the next! One of the hallmarks of operations is its dynamic nature. Things are constantly changing on the plant. From the process variables through to the fabric of the equipment and everything in between. All these changes need to be recognised and controlled in some way to prevent a loss of product quality, interruptions to production, or potential safety incidents.
As a process engineer supporting operations your main job is to figure out what variables are important to the business and ensure adequate controls are in place and working. Over and above this, there are usually a million and one requests for information from all sorts of people, including projects, business development, central technical functions and commercial departments. All of whom want to mess with your plant in some way!
So how do you survive and thrive as a process engineer supporting operations? Some initial thoughts which I’ll come back to and develop in a later post.
1. Accept the fact – things will change hour to hour, day to day, week to week, month to month…..and as a result you need to hold priorities loosely or re-frame them at a macro level in terms of overall business objectives which largely don’t change.
2. Get to know the plant. Where is it ticklish, what changes is it particularly sensitive to, what are its real limits, what margins does it need to operate stably? This requires careful observation over time to identify patterns. And it requires regular communication with control room operators.
3. Establish the root causes of operating problems and go after them relentlessly. This requires a working knowledge of the equipment and how all the components are linked together. Process engineers are responsible for the “process” i.e. the series of sequential steps used to transform raw materials to finished products. Therefore, for any issue, you need to go back upstream to look for potential causes and go downstream to establish how the issue affects the rest of the plant. Pay particular attention to recycles and points of accumulation. These can be at a chemical component level as well as total material.
4. Accept the fact – there will always be more to do than time available to do it. You need to be selective in choosing which problems to work on. #2 and #3 above are critical to selecting the right things.